재귀와 반복문에 대한 생각

코테를 풀다보면 분할정복 등 재귀 알고리즘을 종종 사용하게 됩니다.
이럴 때 마다 재귀를 사용할지 반복문으로 바꿔서 풀지 고민하게 되는데,
이번 포스트에서 재귀와 반복문의 차이, 효율성 등을 비교 해보겠습니다.
재귀
재귀함수는 함수가 자기 자신을 다시 호출하여 문제를 해결하는 프로그래밍 기법입니다. 복잡한 문제를 작고 쉬운 문제로 분할하여 해결하는 분할정복, 이진탐색, 퀵정렬, 팩토리얼, 피보나치 수열 과 같은 문제의 해결에 주로 사용됩니다.
재귀의 단점
Call Stack
재귀함수의 대표적인 단점은 많은 메모리 소모와 이에 따른 속도 저하입니다.
함수가 호출될 때, 프로그램 내부에서는 코드 실행에 사용되는 메모리 뿐만 아니라 함수 실행에 필요한 추가적인 정보(반환 주소, 지역 변수, 매개변수 등)를 담은 스택 프레임(Stack Frame)이 함수 호출 스택(Call Stack)에 쌓입니다.
쉬운 예시로 팩토리얼을 들어보겠습니다.
def fact_rec(n): #재귀
if n <= 1:
return 1
else:
return n * fact_rec(n - 1)코드를 실행하는 동안 함수 호출 스택(Call Stack)의 대략적인 구조는 아래와 같습니다.
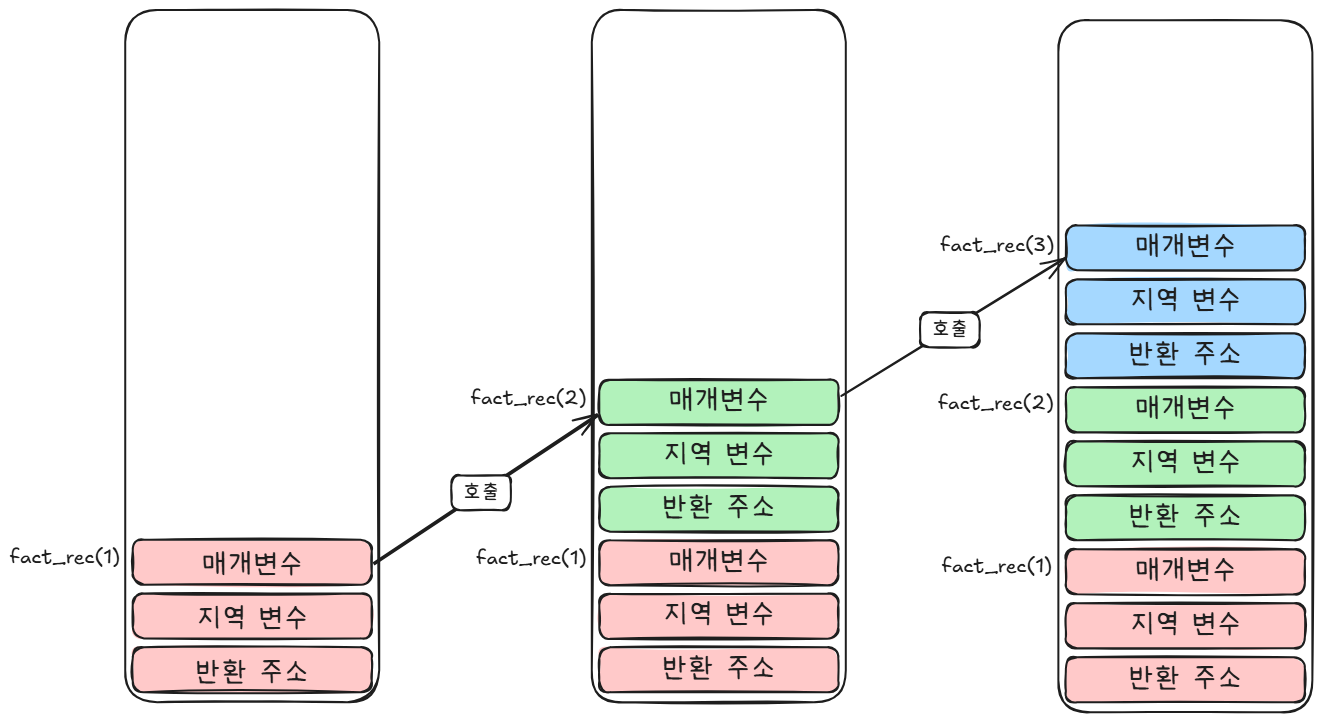
이처럼 함수 호출 스택(Call Stack)에 많은 Stack Frame이 쌓이면 메모리 사용량을 급격히 증가시킵니다. 메모리 뿐만 아니라 스택 프레임을 생성하고 필요한 정보를 저장하고, 실행이 완료되면 스택에서 제거(팝)하는 과정 자체가 상당한 시간 비용을 발생시킵니다.
Stack Overflow
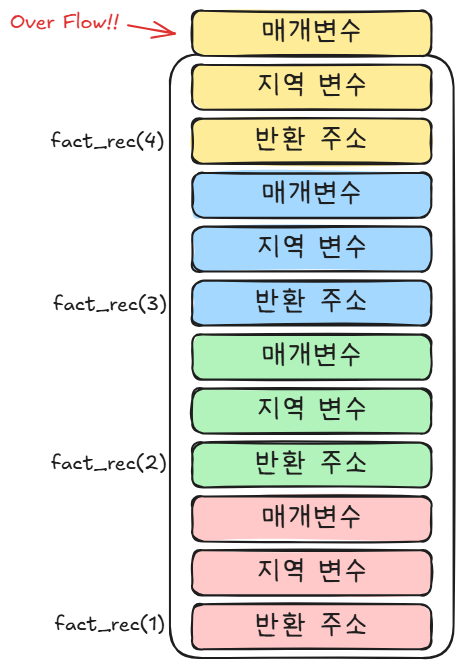
모든 자원이 그렇듯 스택에도 제한된 크기가 있습니다.
만약 재귀호출이 너무 깊어져 스택에 할당된 메모리를 초과한다면 프로그램이 정상적으로 작동하지 않을 것입니다.
Debugging
재귀는 함수가 자기 자신을 반복적으로 호출하기 때문에 호출 스택이 깊어지고 따라기 어렵습니다. 반복문은 변수의 상태가 한눈에 보이지만, 재귀의 경우 특유의 구조때문에 상태를 직관적으로 이해하기 어렵습니다.
직접 비교해보자(팩토리얼)
코드
import timeit, tracemalloc, sys
sys.setrecursionlimit(6000)
repeat = int(input())
def fact_rec(n):
if n <= 1:
return 1
else:
return n * fact_rec(n - 1)
def fact_iter(n):
result = 1
while(n > 1):
result *= n
n -= 1
return result
def measure_memory(func, n):
tracemalloc.start()
func(n)
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
return peak
setup = '''
from __main__ import fact_rec, fact_iter
n = 500
'''
print(f"time_rec = {timeit.timeit('fact_rec(n)', setup=setup, number=repeat):.6f}s")
print(f"time_iter = {timeit.timeit('fact_iter(n)', setup=setup, number=repeat):.6f}s")
print(f"mem_rec = { measure_memory(fact_rec, repeat) / 1024:.2f} KiB")
print(f"mem_iter = {measure_memory(fact_iter, repeat) / 1024:.2f} KiB")설명
fact_rec 는 재귀를 사용, fact_iter은 반복문을 사용해 팩토리얼을 구하는 함수 입니다. 비교를 위해 두 함수를 가능한 한 논리적 흐름이 같도록 구성하였습니다.
repeat를 입력받아, repeat번째 팩토리얼을 구하는데 걸리는 시간과 메모리를 구합니다.
timeit.timeit는 전달받은 함수를 number만큼 반복하여 걸린 시간을 반환합니다.tracemalloc모듈은 파이썬이 할당한 메모리 블록을 추적하는 디버그 도구입니다. tracemalloc.get_traced_memory()를 통해 함수가 실행되는 동안 사용한 메모리의 최대크기를 측정합니다.
결과
| repeat | 100 | 500 | 1000 | 2000 | 3000 | 4000 | 5000 |
|---|---|---|---|---|---|---|---|
| time_rec | 0.006736s | 0.033484s | 0.071856s | 0.136427s | 0.203461s | 0.281862s | 0.331289s |
| time_iter | 0.006802s | 0.025788s | 0.046602s | 0.093743s | 0.136351s | 0.179186s | 0.222362s |
| mem_rec | 0.20 KiB | 8.09 KiB | 23.71 KiB | 54.96 KiB | 86.21 KiB | 117.46 KiB | 148.71 KiB |
| mem_iter | 0.20 KiB | 1.04 KiB | 2.28 KiB | 5.02 KiB | 7.96 KiB | 11.02 KiB | 14.18 KiB |
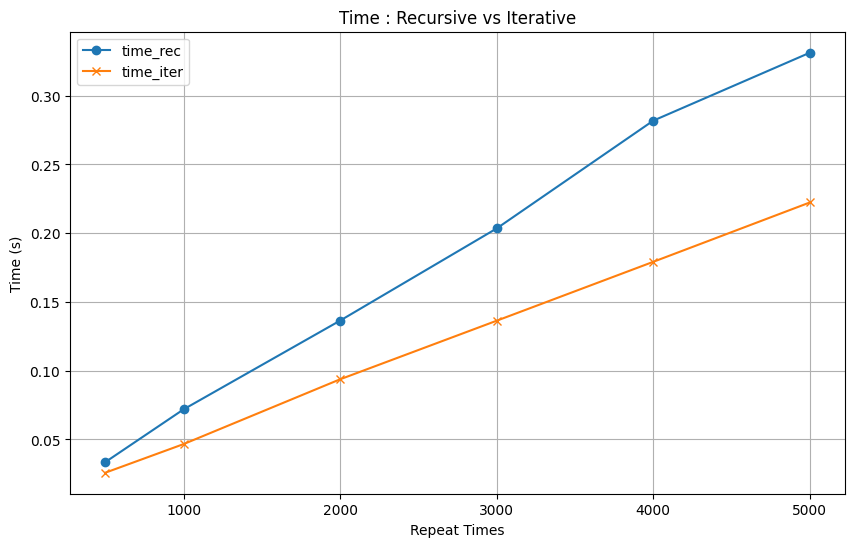
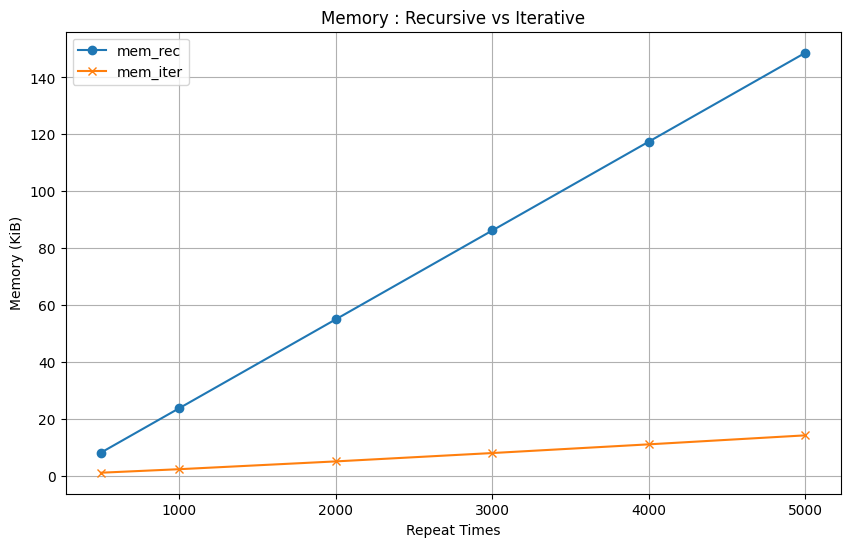
이처럼 시간은 약 1.6배, 메모리는 약 10배정도 차이난다는 것을 알 수 있습니다.
해결방법 - 꼬리재귀(tail call recursion)
// Basic Recursion
int factorial(int n, int total) {
if (n === 1) {
return 1;
}
return n * factorial(n-1);
}
// Tail Recursion(꼬리재귀)
int factorial(int n, total) {
if (n === 1) {
return 1;
}
return factorial(n - 1, n * total);
}두 코드를 비교 해보면 반환부에 연산이 없다는 차이를 알 수 있습니다.
꼬리재귀는 반환부에 연산이 없을 시 컴파일러가 콜스택에 스택프레임을 쌓아두지 않고 반복문처럼 바로바로 반환하여 자체적으로 최적화를 하는 방법 입니다.
하지만 python등 꼬리재귀를 지원하지 않는 언어도 있어서 완벽한 해결책은 아닙니다.
마치며,,
재귀는 간결함에 그 아름다움과 편리함이 있지만, 시간·메모리 비효율이 발생하는 만큼 적절한 곳에서 사용하는 것이 좋습니다.